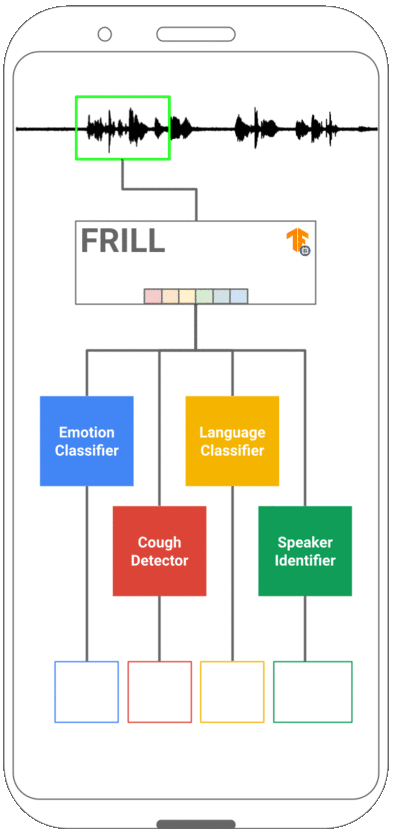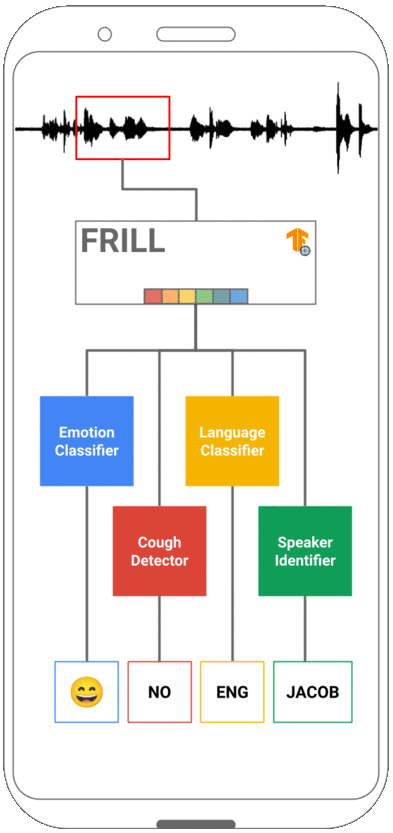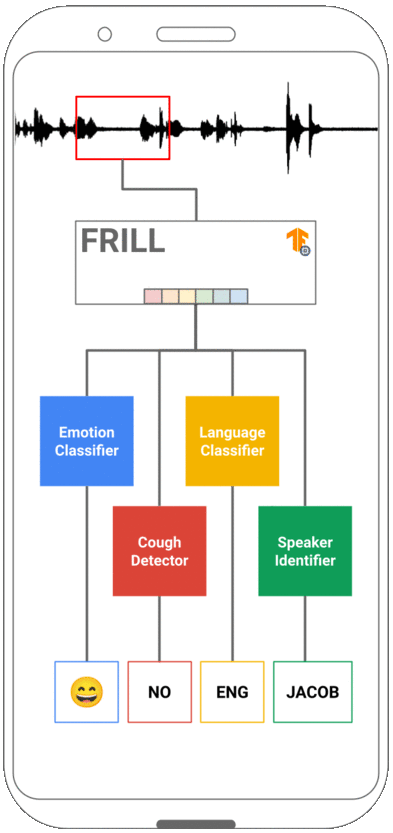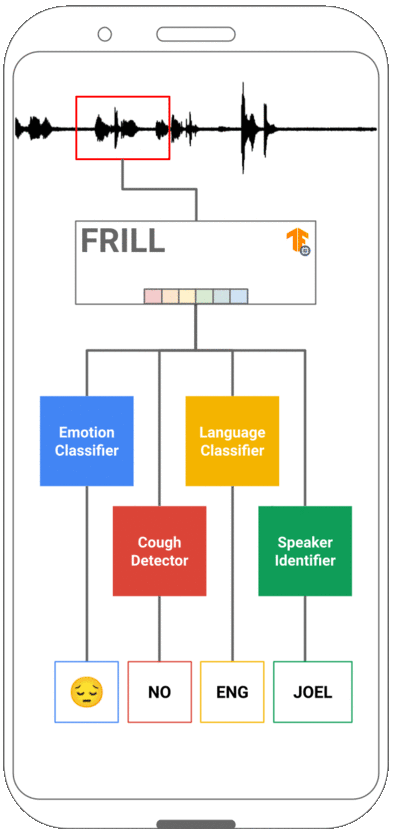
FRILL: A Non-Semantic Speech Embedding for Mobile Devices
@inproceedings{peplinski21_interspeech,
author={Jacob Peplinski and Joel Shor and Sachin Joglekar and Jake Garrison and Shwetak Patel},
title={{FRILL: A Non-Semantic Speech Embedding for Mobile Devices}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={1204--1208},
doi={10.21437/Interspeech.2021-2070}
}
FRILL: A Non-Semantic Speech Embedding for Mobile Devices
Peplinski, J., Shor, J., Joglekar, S., Garrison, J., Patel, S. (2021) FRILL: A Non-Semantic Speech Embedding for Mobile Devices. Proc. Interspeech 2021, 1204-1208, doi: 10.21437/Interspeech.2021-2070
Abstract
Learned speech representations can drastically improve performance on tasks with limited labeled data. However, due to their size and complexity, learned representations have limited utility in mobile settings where run-time performance can be a significant bottleneck. In this work, we propose a class of lightweight non-semantic speech embedding models that run efficiently on mobile devices based on the recently proposed TRILL speech embedding. We combine novel architectural modifications with existing speed-up techniques to create embedding models that are fast enough to run in real-time on a mobile device and exhibit minimal performance degradation on a benchmark of non-semantic speech tasks. One such model (FRILL) is 32× faster on a Pixel 1 smartphone and 40% the size of TRILL, with an average decrease in accuracy of only 2%. To our knowledge, FRILL is the highest-quality non-semantic embedding designed for use on mobile devices. Furthermore, we demonstrate that these representations are useful for mobile health tasks such as non-speech human sounds detection and face-masked speech detection. Our models and code are publicly available.